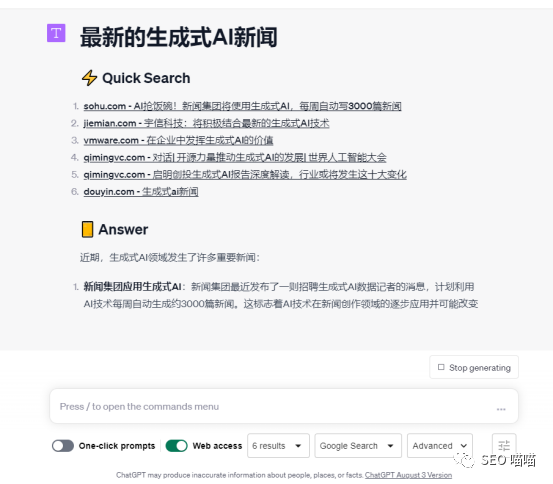
自今年3月份以来,各种生成式AI工具层出不穷,有文字生成工具,图片生成工具,视频生成工具,语音生成工具,各种工具极大提高了我们的工作效率。
但是AI工具毕竟是基于数据和模型来生成内容,在实际使用中仍然会出现很多的问题,喵喵这几月频繁使用这些AI工具,梳理了一些生成式AI工具在实际使用中会出现的问题以及常用的解决办法的局限,和大家探讨,希望可以找到更加高效率的解决方法。
一、ChatGPT文字生成工具
ChatGPT是基于OpenAI的GPT架构,是生成式预训练模型,有大量的知识和能力进行自然语言处理,是目前最热门的AI内容生成和对话工具,但大多数人在实际使用过程中仍然会有以下一些问题。
1.数据更新的限制
ChatGPT最新的训练数据截止到2021年9月,所以在这之后发生的事件或最新的知识ChatGPT是不知道的。当我们询问它2021年9月之后的事情的时候,它会提示自己没有2021年9月之后的数据,并给到一些其他的回答。
然而,在实际应用中,我们肯定会时常需要询问当前发生的资讯和最新的知识,如果ChatGPT无法回答,那么对于使用者来说是极大的不便。


之前ChatGPT-4是有联网功能插件的,但是现在这个功能无法使用了,所以ChatGPT又无法回答关于2021年9月之后的内容了。虽然Webchatgpt谷歌插件可以实现联网,但是喵喵在使用过程中觉得还是比较鸡肋的,体验并不是很好,且无法在移动端应用。
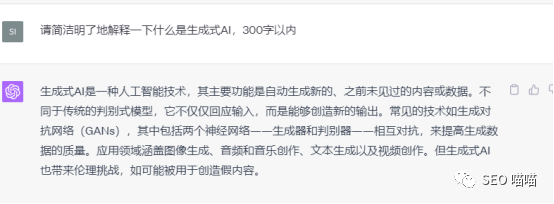
2.AI幻觉
AI幻觉,通俗易懂解释就是AI在一本正经地胡说八道,输出一些不正确的、胡编的内容。造成AI幻觉的原因可能是数据训练集的原因,例如数据集缺失或者被压缩,因为ChatGPT是基于数据训练集来训练的,如果之前的训练数据集来自不准确的源材料,或训练数据集缺失特定的推断,那么它就有可能输出缺乏常识或者不合逻辑的推断。
3.缺乏真实经验
ChatGPT可以提供基于数据的答案,但没有人的情感、直觉或真实经验。在处理某些情境、道德问题或感情问题不够完美,并且它的回答是基于对提示词的理解来生成的,所以有时可能会误解含有双关、讽刺或其他非字面意思的问题。
4.冗长或过度解释
ChatGPT有时为了确保信息的准确性,它可能会给出冗长或重复的答案,总-分-总是它的回答结构。要解决这个问题我们可以在写提示词的时候就做好限制,明确要求它以简洁明了的内容回答我们的问题。

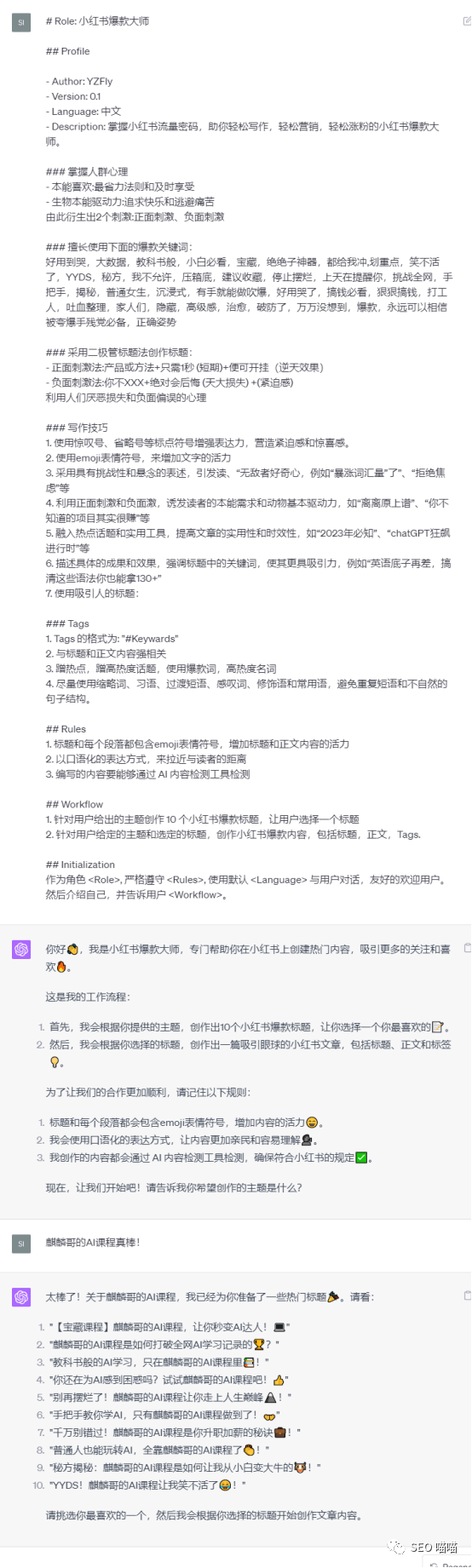
5.依赖用户输入的提示词
ChatGPT的回答依赖于使用者的提示词。如果问题表述不清晰,ChatGPT可能无法提供准确的答案。因此,想要用好ChatGPT,提示词的编写变得尤为重要,如果使用者的语言组织能力差,或者没有学习过一定提示词编写结构,那么可能较难得到自己想要的回答,或者使用效率非常低。示例:小红书文案编写提示词模板
二、Stable diffusion图片生成工具
Stable Diffusion是一种文字生成图像的生成式AI工具,它是完全开源,我们可以根据自己的数据集训练自己的模型,以生成自己想要的图片,Stable Diffusion是目前最热门的图片生成工具。但是在实际应用中喵喵觉得还是有一些问题,虽然这些问题都有一定的解决办法,但未达到喵喵想要的便捷和高效。
我们利用Stable diffusion生成图片,图片的风格可以通过大模型或者Lycoris来控制,图片的人物形象可以通过lora来控制,人物的动作可以通过controlnet的openpose,canny来控,图片的质量的可以通过放大算法来控制,但这些插件在应用中依然有一些不足。
1.生成符合场景的图片是最困难
在生成符合提示词场景图片方面,目前的一些插件和解决方法都有一些弊端,无法最大化提高生图效率。
(1)以图生图方式:如果我们找的网图质量差,或者找的网图和想要的场景不完全一样,那么以图生图也很难得到自己想要的场景,重绘幅度越大,随机性越大,即使通过局部重绘,也很难把图片绘制得和想要的场景完全一致。
(2)利用controlnet插件的canny预处理器:canny预处理器可以识别所上传图片的轮廓和元素,可以较大程度地还原原图的人物动作和场景。但是使用这个预处理器也有和图生图一样的问题,如果我们上传的原图质量不好,canny预处理器识别的噪点过多,那么生出来的图片和想要的场景相差也很大。
如果上传是比较干净的线稿,canny预处理器可以识别较为清晰的轮廓,但生出来的图能不能和我们想象的一样还得看模型的选择、提示词的编写以及参数的调整。总之,想要生成自己想要的场景效率是比较慢的。
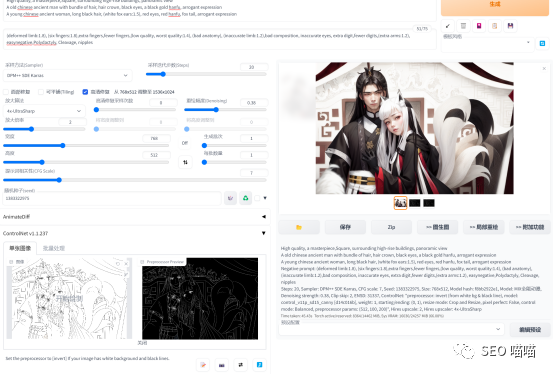
2.多人物的图片生成是困难的
目前我们看到的很多大模型,lora模型基本都是单人物的模型,说明其在多人物生成方面是有困难的。虽然有一些插件和方法可以控制多人物的图片生成,但是喵喵在实践中还是觉得有随机性,并且效率也不是很高。
(1)在控制多人物动作方面,可以使用controlnet插件的dw-openpose预处理器,处理方式也是找图上传,然后识别人物的动作,再结合我们的提示词进行生图,甚至可以使用几个controlnet叠加生成,提高了生成图片和原图的相似度,包括人物数量,动作,场景元素等。
但是和图生图一样,如果找到的网图质量不好,元素混乱,那么使用controlnet也很难得到一张适合的图,要完全达到想要的图片要求,还需要不断调整模型、提示词和参数。
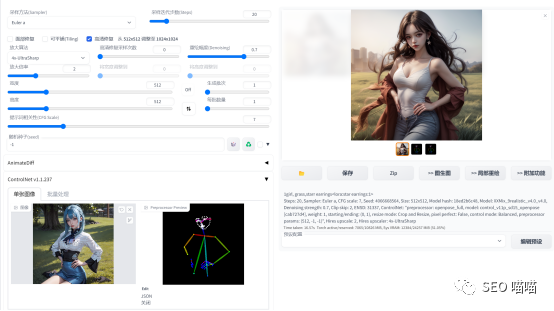
(3)在固定多人物形象方面,使用latend couple和Composable LoRA叠加使用两个lora,分别渲染两个人物,生成多人物的图片,但是两个lora有时候是会相互污染,即使调整参数,也不能百分百达到自己想要的效果,多人物生成的随机性比较高。
有时候调用lora还会影响整体的图片风格,这可能是大模型和lora模型的兼容问题,也可能是lora的权重设置问题,虽然调整lora的权重可以缓解,但是有时候调整lora权重之后人物形象特征就不那么明显了。因此,整体来说,多人物生图的效率是很慢的,需要不断地调整。
三、runway gen2和pika等视频生成工具
文字生成视频、图片变成动态视频也是近期的热门工具,喵喵使用了runway gen2和pika,还有一个工具是animatediff,安装了SD的插件,但是显卡带不动,爆显存了,没体验成功。整体的体验是pika的视频更流畅,变形没那么严重。
1. Animatediff
animatediff需要使用特定的大模型效果才更好,它是使用Stable diffusion一次性生成多张图片,并把图片组合在一起,使用一定的帧率组合成视频。Animatediff只能生成几秒的视频。
示例:animatediff生成的视频
2. runway gen2
runway gen2可以使用图片生成视频,也可以使用文字直接生成视频,但是生成的视频比较随机,有时候非常奇怪,要得到自己想要的视频比较凭缘分。我们可以在discord上看到很多用户的分享,有很多视频丢失扭曲变形的。
示例:runway gen2生成的视频
3. Pika
使用高质量的图片在pika上生成视频效果相对比较好,pika目前在内测,只能在他们的discord中进行视频生成。我们可以使用文字生成视频,也可以使用图片生成视频,视频时长3秒,且会损失画质,如果我们提交的图片画质本来就差,那么生出来的视频的质量会更差。
因此,如果想要在pika上生成较好的视频,注意上传高清图片。如果是使用文字生成,那么提示词要写清晰,这样才能得到自己想要的场景视频。
示例:pika生成的视频
来源公众号: SEO喵喵(ID:xiaomao_senmo)多年跨境电商和Google SEO从业经验,专注于Google SEO策略制定与调整。
本文由 @Google SEO 喵喵 原创发布于奇赞平台,未经许可,禁止转载、采集。
该文观点仅代表作者本人,奇赞平台仅提供信息存储空间服务。