*上期指路:SEO必备工具:尖叫青蛙(Screaming Frog)的全面教程(一)
因为内容较多,这期就不多废话,接着上期内容继续往下👇

04 Configuration 配置
我们打开配置菜单,可以看到以下选项:
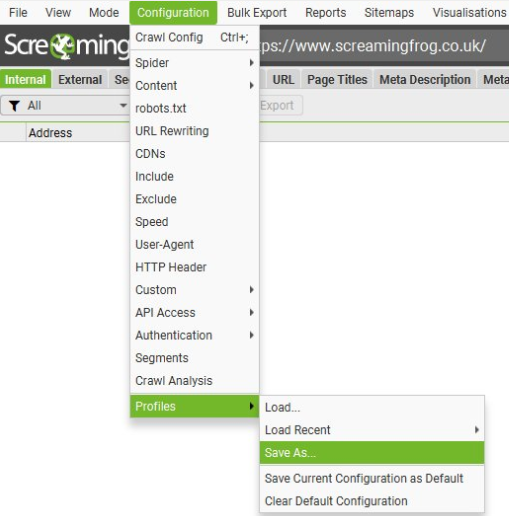
4.1、Crawl Config – 抓取配置
点击Crawl Config会弹出和下面一样的弹窗,所以我们从4.2 spider – 爬虫开始详细讲解
4.2、Spider- 爬虫

4.2.1、Spider Crawl
Resource Links 资源链接
Configuration > Spider > Crawl > Images
取消勾选“爬行”配置意味着不会爬行 img 元素内的图像文件来检查其响应代码。
取消勾选“存储”配置意味着 img 元素内的图像文件将不会被存储,也不会出现在 SEO Spider 中
Configuration > Spider > Crawl > CSS
取消勾选“爬行”配置意味着不会爬行样式表来检查其响应代码。
取消勾选“存储”配置意味着 CSS 文件将不会被存储,也不会出现在 SEO Spider 中。
Configuration > Spider > Crawl > JavaScript
取消勾选“抓取”配置意味着不会抓取 JavaScript 文件来检查其响应代码。
取消勾选“存储”配置意味着 JavaScript 文件将不会被存储,也不会出现在 SEO Spider 中。
Configuration > Spider > Crawl > SWF
取消勾选“抓取”配置意味着不会抓取 SWF(Adobe Flash 文件格式) 文件来检查其响应代码。
取消勾选“存储”配置意味着 SWF 文件将不会被存储,也不会出现在 SEO Spider 中。
Page Links 页面链接
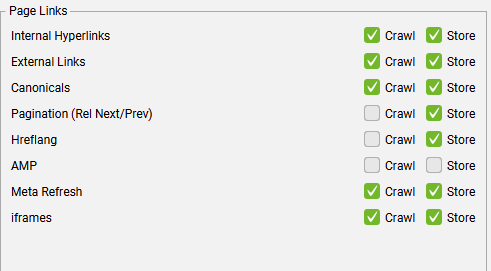
Internal hyperlinks 内部超链接
默认情况下,SEO Spider 将抓取并存储抓取中的内部超链接。
通过禁用“抓取”,与起始 URL 位于同一子域的锚文本内所包含的 URL 将不会被跟踪和抓取。其实就是只抓取当前链接。
在列表模式下,同时禁用“存储”和“抓取”功能会很有用,因为这样可以移除抓取深度 。这样一来,SEO Spider 就可以抓取已上传的 URL 以及任何其他选定的资源或页面链接,但不再抓取内部链接。
External links 外部链接
取消勾选“抓取”配置意味着不会抓取外部链接来检查其响应代码。
取消勾选“存储”配置意味着任何外部链接将不会被存储,也不会出现在 SEO Spider 中。
⚠️注意:这包括图像、CSS、JS、hreflang 属性和规范(如果它们是外部引用的)。
Canonicals 规范标签
Configuration > Spider > Crawl > Canonicals
取消勾选“抓取”配置意味着在规范中发现的 URL 将不会被抓取。如果仅选择“存储”,则这些 URL 将继续在界面中报告,但不会用于发现。
取消勾选“存储”配置意味着规范将不会被存储,也不会出现在 SEO Spider 中。
怎么用?
当页面通过多个 URL 访问时,rel=”canonical” 元素有助于指定一个首选版本。它通过将索引和链接属性合并到单个 URL 中用于排名,来提示搜索引擎如何防止内容重复。
规范选项卡有多个过滤器,我们分别讲一下什么含义。
- Contains Canonical包含规范 URL – 页面已设置规范 URL(通过 link 元素、HTTP 标头或两者同时设置)。这可以是自引用规范 URL,即页面 URL 与规范 URL 相同;也可以是“被规范化 URL”,即规范 URL 与页面 URL 不同。
- Self Referencing自引用 – 该 URL 具有一个规范 URL,该 URL 与被抓取的页面 URL 相同(因此,它是自引用的)。
- Canonicalised规范化 – 该页面拥有一个与其自身不同的规范 URL。该 URL 已被“规范化”到其他位置。这意味着搜索引擎被指示不索引该页面,并且索引和链接属性应合并到目标规范 URL。
- Missing缺失 – 无论是在链接元素中还是在 HTTP 标头中,都没有规范 URL。如果某个页面没有指定规范 URL,Google 会自行判断其最佳版本或 URL。这会导致排名难以预测,因此通常所有 URL 都应指定规范版本。
- Multiple多个 – 一个 URL 被设置了多个规范 URL(多个 link 元素、HTTP 标头,或两者兼有)。这可能会导致不可预测性,因为一个页面应该只设置一个规范 URL。
- Non-Indexable Canonical不可索引的规范网址 – 规范网址是指不可索引的页面。这包括被 robots.txt 屏蔽、无响应、重定向 (3XX)、客户端错误 (4XX)、服务器错误 (5XX) 或“noindex”的规范网址。规范版本的网址应始终是可索引的,且响应“200”的页面。
Pagination (rel next/prev)分页(相对下一个/上一个)
默认情况下,SEO Spider 不会抓取 rel=”next” 和 rel=”prev” 属性或使用其中包含的链接进行发现。
取消勾选“抓取”配置意味着在 rel=”next” 和 rel=”prev” 中发现的 URL 将不会被抓取。
取消勾选“存储”配置意味着 rel=”next” 和 rel=”prev” 属性将不会被存储,也不会出现在 SEO Spider 中。
Configuration > Spider > Crawl > Hreflang
取消勾选“抓取”配置意味着不会抓取在 hreflang 中发现的 URL。
取消勾选“存储”配置意味着 hreflang 属性将不会被存储,也不会出现在 SEO Spider 中。
Configuration > Spider > Crawl > AMP
默认情况下,SEO Spider 不会提取 rel=”amphtml” 链接标签中包含的 AMP URL 的详细信息,这些 URL 随后会出现在 AMP 选项卡下。
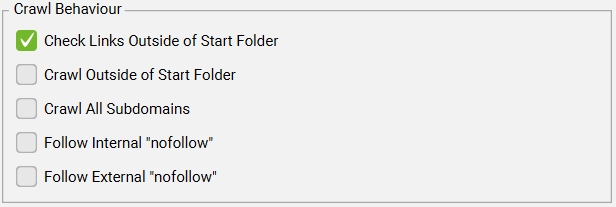
Configuration > Spider > Crawl > Crawl Outside of Start Folder
默认情况下,SEO Spider 只会抓取您从其正向抓取的子文件夹(或子目录)。但是,如果你希望从特定子文件夹开始抓取,但抓取整个网站,要勾选此选项。
Configuration > Spider > Crawl > Crawl All Subdomains
默认情况下,SEO Spider 只会爬取你开始输入的那个子域名,并将遇到的所有其他子域名视为外部网站。这些子域名只会被爬取一层,并显示在“外部”标签页中。
- 只爬取起始子域名:如果你从
www.example.com开始爬取,它只会全面爬取这个子域名。 - 其他子域名当作外部站点:比如你的网站还有
blog.example.com或shop.example.com,这些会被当作“外部链接”处理。 - 只爬取一层:对这些“外部子域名”的链接,工具只会抓取一层,也就是链接页面本身,不会继续深入。
Configuration > Spider > Crawl > Follow Internal/External “Nofollow”
默认情况下,SEO Spider 不会爬取带有 nofollow、sponsored 和 ugc 属性的内部或外部链接,或者来自包含 meta nofollow 标签或 X-Robots-Tag HTTP 头 中包含 nofollow 的页面上的链接。
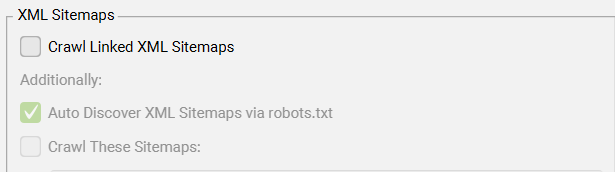
Configuration > Spider > Crawl > Crawl Linked XML Sitemaps
SEO Spider 默认不会抓取 XML 站点地图(在常规“蜘蛛”模式下)。要抓取 XML 站点地图并填充 “站点地图”选项卡中的过滤器,需要启用此配置。
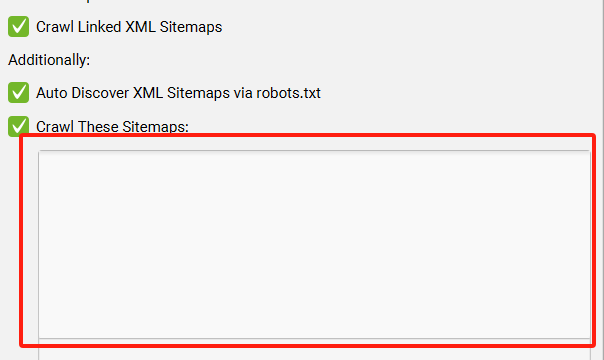
当启用“抓取链接的 XML 站点地图”配置时,您可以选择“通过 robots.txt 自动发现 XML 站点地图”,或者通过勾选“抓取这些站点地图”来提供 XML 站点地图列表,然后将其粘贴到下面的输入框内。
4.2.2、Spider Extraction 爬虫提取
选择要在爬取过程中提取、存储和分析的元素和数据。也就是说明在使用 SEO Spider时,可以自定义爬虫要抓取的内容。你可以决定:
- 要抓取哪些页面元素或数据
(例如标题、元描述、H1 标签、图片、结构化数据等)。 - 是否存储和分析这些数据
下面的选项不做过多解释,勾选就表明提取或储存,不勾选就不会提取或储存。
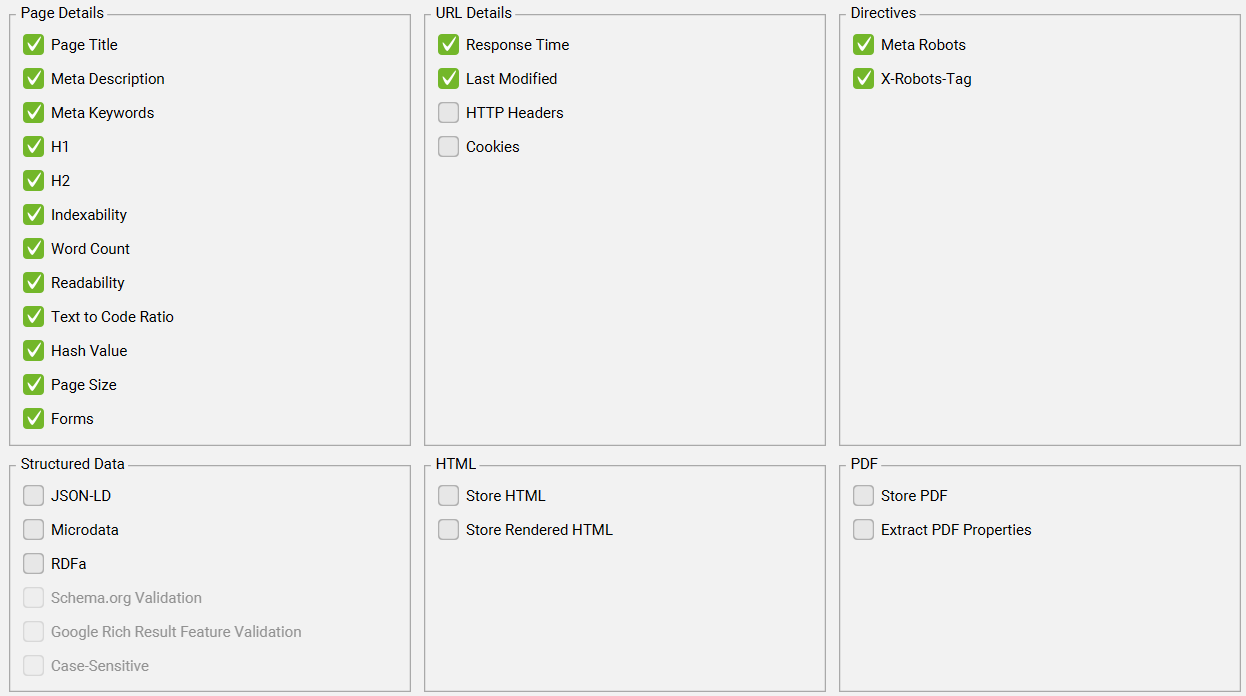
例如,如果“哈希值”被禁用,“URL > 重复”过滤器将不再生效,因为该过滤器使用哈希值作为精确重复 URL 的算法检查。
4.2.3、Spider Limits
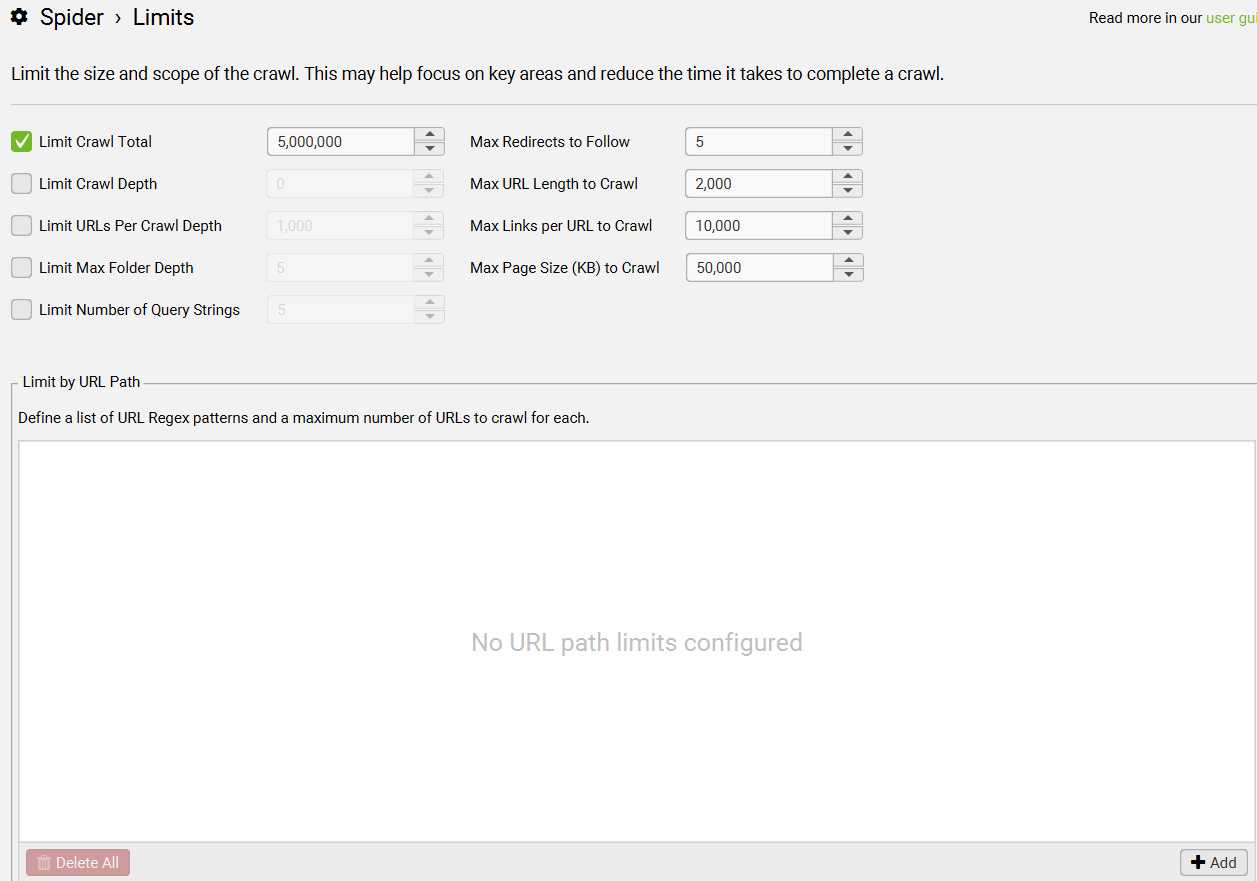
Configuration > Spider > Limits > Limit Crawl Total
该软件的免费版最多抓取 500 个 URL。如果您拥有该工具的授权版本,则最多抓取 500 万个 URL,默认50万个URL。
Configuration > Spider > Limits > Limit Crawl Depth
选择 SEO Spider 抓取网站的深度(就距离您选择的起点的链接而言)。
Configuration > Spider > Limits > Limit URLs Per Crawl Depth
控制每次抓取深度抓取的 URL 数量。
Configuration > Spider > Limits > Limit Max Folder Depth
控制 SEO Spider 将抓取的文件夹(或子目录)的深度,Spider 将文件夹归类为域名后以斜杠结尾的 URL 路径为一层深度。
例如:
-
https://www.abc.com/ – 文件夹深度 0 -
https://www.abc.com/seo-spider/ – 文件夹深度 1 -
https://www.abc.com/seo-spider/#download – 文件夹深度 1 -
https://www.abc.com/seo-spider/fake-page.html – 文件夹深度 1 -
https://www.abc.com/seo-spider/user-guide/ – 文件夹深度 2
Configuration > Spider > Limits > Limit Number of Query Strings
限制查询参数数量
例如,如果设置为 “2”,那么像 example.com/?query1&query2&query3 这种带有 3 个查询参数的链接将不会被爬取。
Configuration > Spider > Limits > Limit Max Redirects to Follow
此选项可以控制 SEO Spider 将遵循的重定向次数。
Configuration > Spider > Limits > Limit Max URL Length
控制 SEO Spider 将抓取的 URL 的长度。由于数据库存储的限制,默认的最大 URL 长度为 2,000。
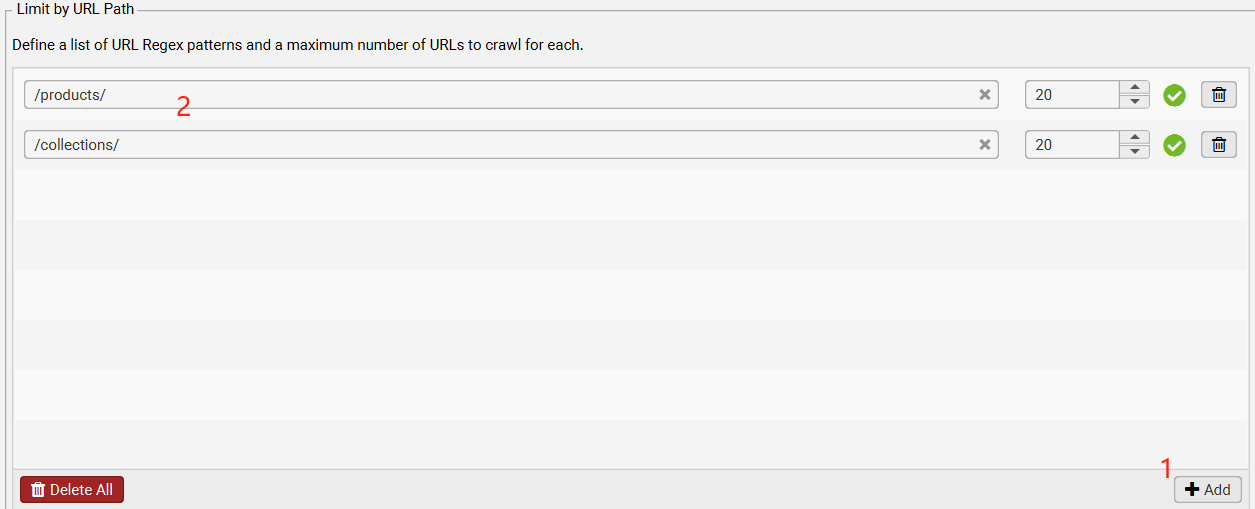
Configuration > Spider > Limits > Limit by URL Path
这个功能可以让你按不同网址分类,限制每类最多抓多少个页面,从而节省时间、内存、提高效率。
假设你的网站有很多不同类型的页面,比如:
-
产品页: https://www.example.com/products/123 -
博客页: https://www.example.com/blog/article-1 -
帮助中心页: https://www.example.com/help/faq
你可以告诉 SEO Spider:
-
对 /products/这类页面,最多爬 500 个; -
对 /blog/这类页面,最多爬 100 个; -
对 /help/的页面,最多爬 50 个。
设置方法:
点击 Add(添加)。
在 URL Path Pattern 中输入:
4.2.4、Configuration > Spider > Rendering(渲染设置)
1). Text Only(仅文本模式)
SEO Spider 只会从原始 HTML 中爬取和提取内容。
它会忽略 AJAX 爬取方案(AJAX Crawling Scheme)和客户端 JavaScript 脚本。
2). Old AJAX Crawling Scheme(旧版 AJAX 爬取方案)
如果页面使用了 Google 早期设计的 AJAX 爬取方式(现在已经被废弃),SEO Spider 会遵循它。
如果页面没有使用该方案,它就跟 “Text Only” 模式一样工作。(⚠️ 目前很少用了,仅适用于老旧网站。)
3). JavaScript(JavaScript 渲染模式)
SEO Spider 会像浏览器一样执行网页里的客户端 JavaScript(使用无头 Chrome 浏览器)。它会从渲染后的 HTML 页面中提取内容和链接,同时也会提取原始 HTML 中的链接,就像 Google 爬虫一样。
4.2.5、Spider Advanced
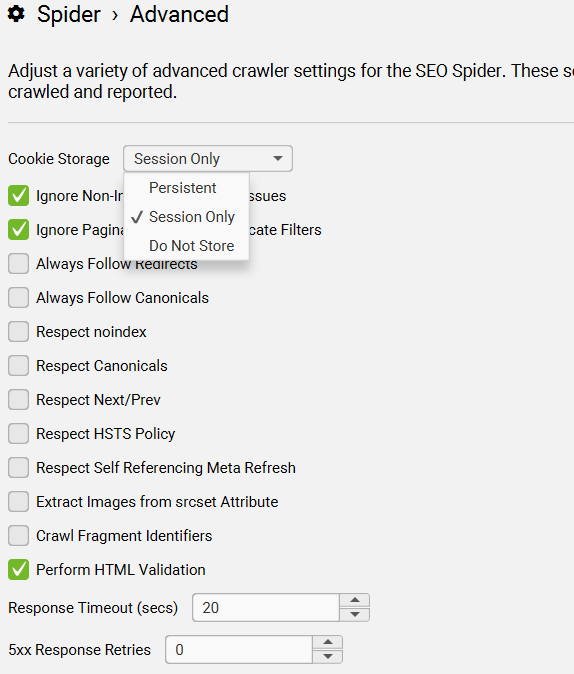
Configuration > Spider > Advanced > Cookie Storage
Google 会在没有 Cookie 的情况下无状态抓取网页,但会在页面加载期间接受 Cookie。某些网站只有在接受 Cookie 的情况下才能访问,如果禁用 Cookie,则会访问失败。
默认情况下,SEO Spider 会“仅在会话期间”接受 Cookie。这意味着它们会在页面加载时被接受,加载完成后会被清除。
您可以选择将 cookie 存储切换为“持久性”,这将在会话期间记住 cookie,或者选择“不存储”,这意味着它们根本不会被接受。
启用后,SEO Spider 仅在页面可索引时才会填充与问题相关的过滤器。这包括页面标题、元描述、元关键词、H1 和 H2 标签下的所有过滤器
这个选项的作用是:只对 Google 能够索引的页面报告问题,忽略不能被索引的页面。
举例:如果某个页面设置了noindex,被视为“不可索引”,那么它将不会被算作“重复标题”、“标题过长/过短”等问题的一部分。
Configuration > Spider > Advanced > Ignore Paginated URLs for Duplicate Filters
当启用此选项时,带有 rel="prev" 的分页页面将不会被计入以下标签页的“重复”筛选项中:
-
页面标题(Page Titles) -
元描述(Meta Description) -
Meta 关键词(Meta Keywords) -
H1 和 H2 标签
只有分页序列中的第一页(带有 rel="next" 属性的页面)会被用来检查是否重复。
假设你有一个分页的产品列表:
-
第 1 页: /products?page=1 -
第 2 页: /products?page=2,包含rel="prev"指向第 1 页 -
第 3 页: /products?page=3,也包含rel="prev"
这些分页页面的标题可能是一样的,比如都是 “xxx Products – Page”。如果不忽略它们,工具会把它们标记为“重复标题”。
但启用这个设置后,SEO Spider 就会认为这是正常的分页行为,不再标记为重复,只检查第一页的内容。
Configuration > Spider > Advanced > Always Follow Redirects
这个功能允许 SEO Spider 在**列表模式(List Mode)**下,不受抓取深度限制地持
续跟踪重定向,直到最终目标 URL。
这在网站迁移过程中尤其有用,因为某些 URL 可能会经过多次 3XX 重定向(如 301 或 302)后才到达最终页面。
SEO Spider 会一直跟随重定向链条,直到最终 URL 为止。
比如:A → 301 → B → 302 → C → 301 → D 蜘蛛会一直爬到 D,而不是只停在 B。
Configuration > Spider > Advanced > Always Follow Canonicals
此功能允许 SEO Spider 在列表模式下跟踪规范链接,直至到达最终的重定向目标 URL,而无需考虑爬取深度。此功能对于网站迁移尤其有用,因为规范链接在到达最终目标 URL 之前可能会被多次规范化。
Configuration > Spider > Advanced > Respect Noindex
此选项意味着带有“noindex”的网址不会被 SEO Spider 报告。这些网址仍会被抓取,其外部链接也会被跟踪,但它们不会出现在工具中。
是否建议开启?
如果你只关注 SEO 相关的页面(可被 Google 收录的),建议开启。
如果你想全面审核整个网站的结构、链接或内容,包括 noindex 页面,则不建议开启。
Configuration > Spider > Advanced > Respect Canonical
同上,不再赘述。
Configuration > Spider > Advanced > Respect Next/Prev
启用此选项后,在分页序列中带有 rel="prev" 的页面将不会显示在 SEO Spider 的报告中。只有分页序列中的第一个页面会被报告和显示。
Configuration > Spider > Advanced > Respect HSTS Policy
当启用此选项时,SEO Spider 会遵守 HSTS 策略,即使链接指向 HTTP 页面,SEO Spider 也会通过 HTTPS 访问该页面。
在这种情况下,SEO Spider 会显示以下信息:
- 状态码(Status Code):307
- 状态(Status):HSTS Policy
- 重定向类型(Redirect Type):HSTS Policy
你可以禁用此功能,查看重定向背后的“真实”状态码(例如:301 永久重定向)。
Configuration > Spider > Advanced > Respect Self Referencing Meta Refresh
你可以禁用 “尊重自我引用的 Meta Refresh” 配置,这样SEO Spider 就不会将自我引用的 meta refresh URL 视为“不可索引”。
Configuration > Spider > Advanced > Extract Images From IMG SRCSET Attribute
如果启用此选项,SEO Spider 将从 <img> 标签的 srcset 属性中提取图片。
是否建议开启?
建议开启,尤其是当你希望确保抓取到所有设备适配的图片,或者在进行图像 SEO 优化时。
Configuration > Spider > Advanced > Crawl Fragment Identifiers
如果启用,SEO Spider 将抓取带有哈希片段的 URL 并将其视为单独的唯一 URL。
https://abc.com/#this-is-treated-as-a-separate-url/
Configuration > Spider > Advanced > Perform HTML Validation
如果启用此选项,SEO Spider 会检查网页中的基础 HTML 错误,这些错误可能会影响爬虫抓取或页面被搜索引擎索引。
SEO Spider 可以帮助你识别一些常见问题,例如:
<title>、<meta>标签放在<body>而不是<head>中;-
标签嵌套错误、未闭合的标签; -
多个 <head>或<html>元素等。
Configuration > Spider > Advanced > Response Timeout (secs)配置 > 蜘蛛 > 高级 > 响应超时(秒)
默认会等待 20 秒来获取来自 URL 的任何 HTTP 响应。对于速度非常慢的网站,您可以增加等待时间。
Configuration > Spider > Advanced > 5XX Response Retries
此选项提供自动重试 5XX 响应的功能。这些响应通常是临时的,因此重试 URL 可能会返回 2XX 响应。
4.2.6、Spider Preferences
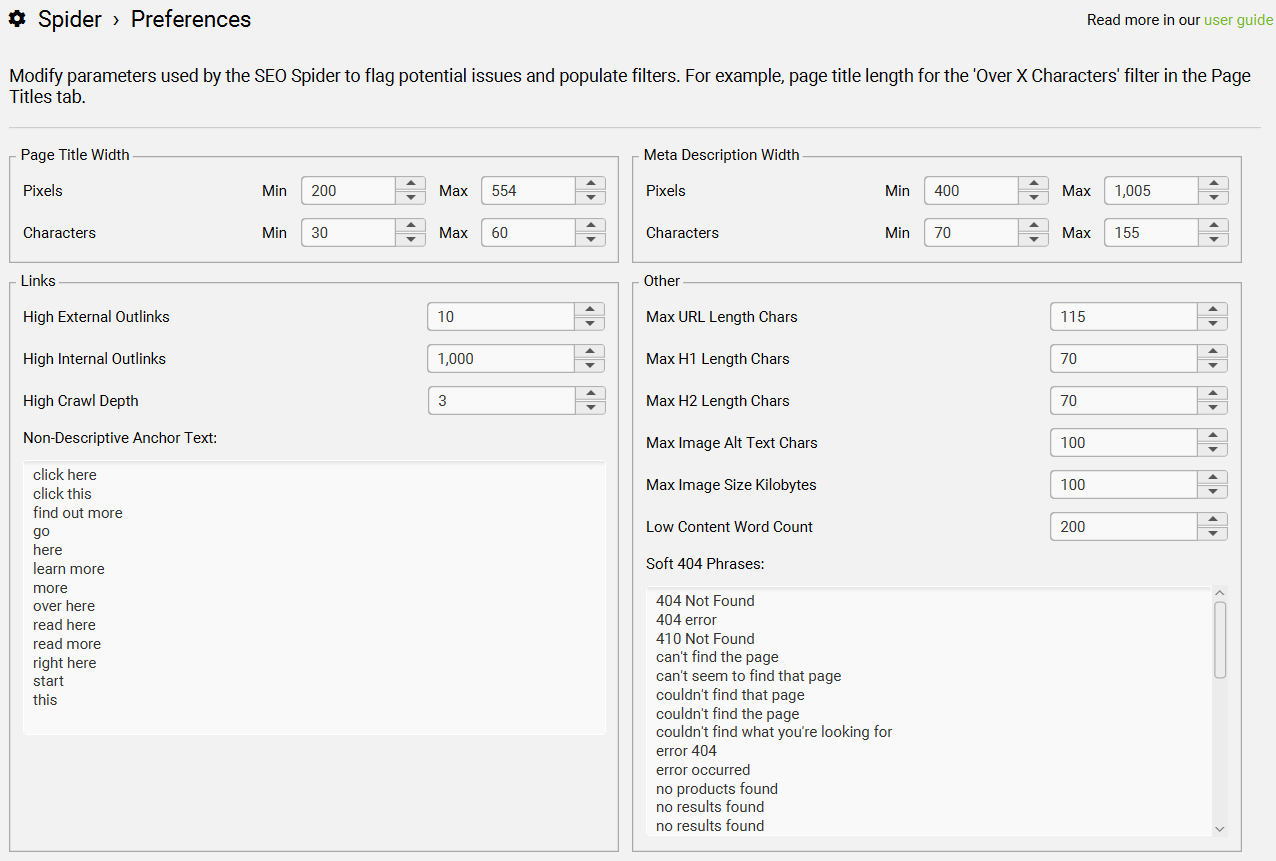
Configuration > Spider > Preferences > Page Title/Meta Description Width
此选项允许你自定义 SEO Spider 中“页面标题”和“Meta 描述”标签页中字符数和像素宽度的限制值。
例如:
-
如果你将“页面标题宽度”的最小像素值从默认的 200改为150, -
那么在 “Page Titles” 标签页中的过滤器就会从 “Below 200 Pixels(低于 200 像素)” 变为 “Below 150 Pixels(低于 150 像素)”。
你可以根据自己的需求设定字符数和像素宽度的标准。
Configuration > Spider > Preferences > Links
这些选项允许你自定义 SEO Spider 在 “Links”(链接) 标签页中,以下几类过滤器触发的阈值:
- Pages With High External Outlinks(外部链接过多的页面)
- Pages With High Internal Outlinks(内部链接过多的页面)
- Pages With High Crawl Depth(爬取层级过深的页面)
- Non-Descriptive Anchor Text In Internal Outlinks(内部链接中锚文本不具描述性的页面)
例如:
将“High Internal Outlinks”的默认值从1000改为2000,表示:只有当某页面包含 2,000 个或更多的内部出链时,才会被列入此过滤器结果。
这个设置是让你可以调整判断页面链接数量是否“异常”的标准:
-
有些网站规模大、页面之间互链多,可能内部出链上千是正常的; -
有些页面的爬取深度超过几层不一定是问题; -
锚文本不够描述性可能影响 SEO,但你可能只需要关心最严重的情况。
是否建议调整?
建议根据你的网站规模和结构进行适当调整。
例如:
-
企业官网页面少,内部链接正常值可能几十个; -
大型电商网站,几百上千个内部出链可能是常态。
Configuration > Spider > Preferences > Other
这些选项可以控制各自选项卡中的 URL、h1、h2、图像替代文本、最大图像尺寸和低内容页面过滤器的字符长度。
4.3、content – 内容

Configuration > Content > Area
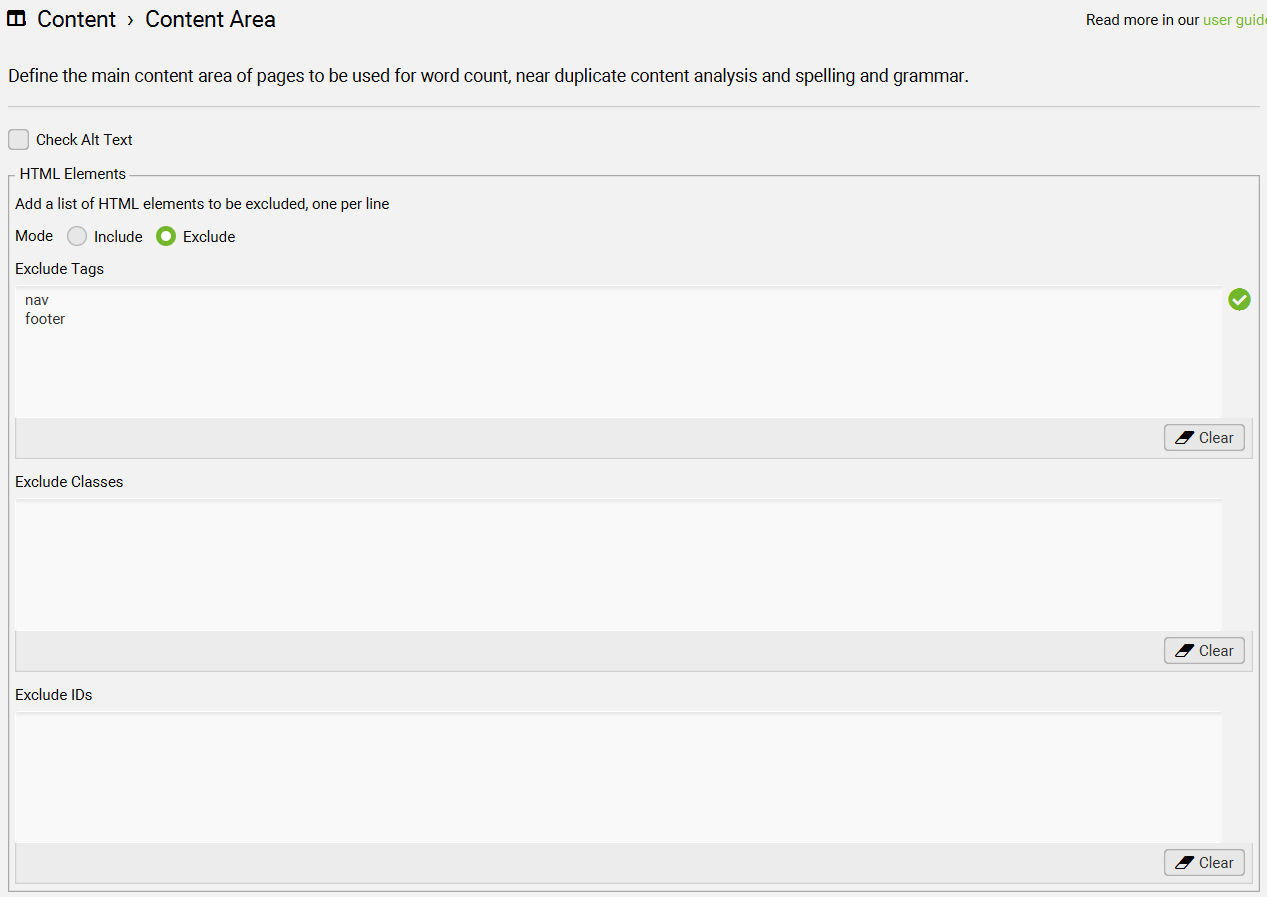
你可以指定 SEO Spider 在分析以下内容时所使用的“内容区域”:
-
词数统计 -
相似内容(near duplicate)检测 -
拼写与语法检查
这样可以让分析更专注于页面的“主要内容区域”,而避免干扰性强的公共模板内容(如导航、页脚等)。
Configuration > Content > Duplicates
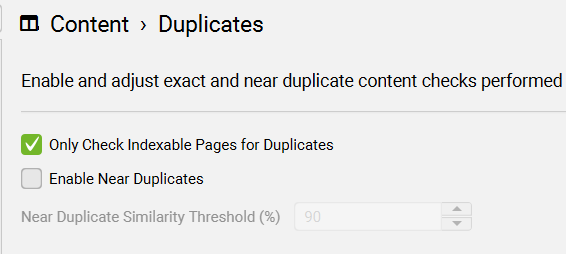
SEO Spider 能够查找完全重复(即页面彼此完全相同)以及近似重复(即不同页面之间存在部分内容匹配)。您可以在“内容”选项卡及其对应的“完全重复”和“近似重复”过滤器中查看这两项内容。
Configuration > Content > Spelling & Grammar
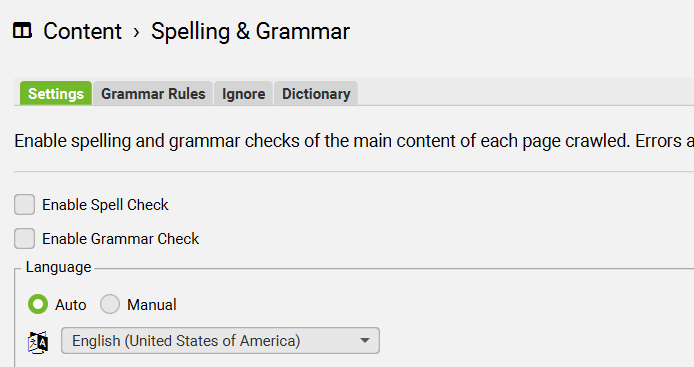
SEO Spider 能够对抓取的 HTML 页面进行拼写和语法检查。
拼写和语法检查默认是禁用的,需要启用才能在“内容”选项卡中显示拼写和语法错误,以及相应的“拼写错误”和“语法错误”过滤器。
拼写和语法功能将自动识别页面上使用的语言(通过 HTML 语言属性),但也允许您在配置中根据需要手动选择语言。
4.4、robots.txt – robots.txt
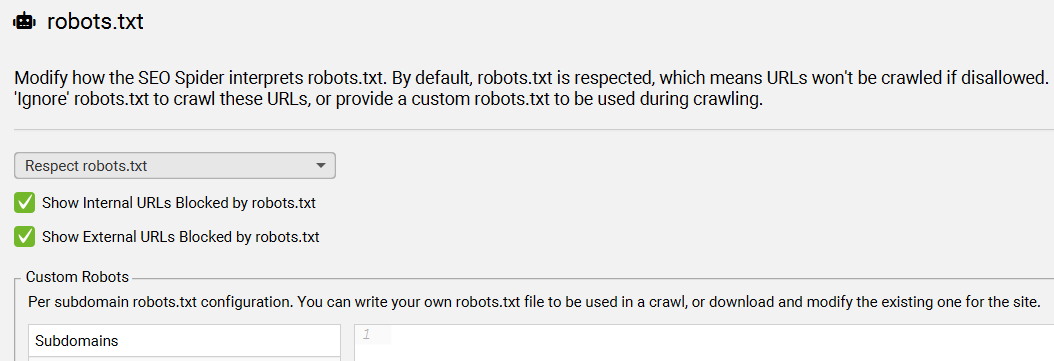
默认情况下,SEO Spider 将遵循 robots.txt 协议,并设置为“尊重 robots.txt”。这意味着,如果 robots.txt 禁止 SEO Spider 抓取某个网站,则 SEO Spider 将无法对其进行抓取。
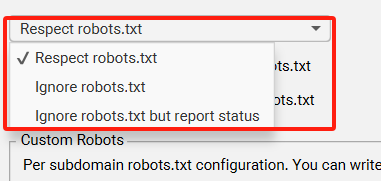
此设置可以调整为“忽略 robots.txt”或“忽略 robots.xt 但报告状态”。
Show Internal URLs Blocked By Robots.txt
- 显示被 robots.txt 阻止的内部 URL:启用后,你可以查看哪些内部链接被 robots.txt 文件阻止,这有助于你了解哪些页面搜索引擎无法访问。
Show External URLs Blocked By Robots.txt
- 显示被 robots.txt 阻止的外部 URL:启用后,你还可以看到外部网站的链接(即你网站链接到其他网站的外部链接)是否被 robots.txt 文件阻止。
Custom Robots
你可以使用自定义 robots.txt功能来下载、编辑和测试网站的 robots.txt 文件,这样它将在抓取过程中覆盖网站上实际的 robots.txt 文件。但请注意,这不会更新网站上的实际 robots.txt 文件,只会影响本次抓取过程。
4.5、URL Rewriting – URL重写
URL重写功能让你能够在抓取过程中修改 URL,例如去掉不必要的跟踪参数(如 utm_source),或者统一将 HTTP 链接改为 HTTPS。
Remove Parameters
此功能允许你自动移除 URL 中的参数。对于带有会话 ID、Google Analytics 跟踪或很多你希望移除的参数的网站来说,这非常有用。例如:
-
如果网站的 URL 包含会话 ID(如: example.com/?sid=random-string),你只需在‘移除参数’标签中添加sid,SEO Spider 就会自动将这个会话 ID 从 URL 中去除。
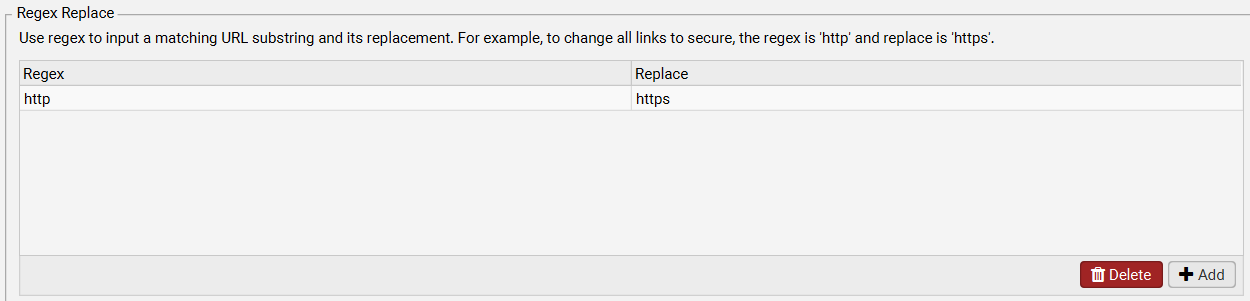
Regex Replace
这是一个高级功能,它会对抓取到的每个 URL 或列表模式中的 URL 运行正则表达式,替换匹配正则的子串。
这是一个高级功能,它会对抓取到的每个 URL 或列表模式中的 URL 运行正则表达式,替换匹配正则的子串。
例如:
将所有链接从 HTTP 改为 HTTPS
-
正则表达式: http -
替换为: https
4.6、CDNs – 内容分发网络
CDNs 功能允许你输入一个 CDN(内容分发网络)列表,在抓取过程中将这些域名视为“内部链接”。
你可以提供一组域名,这些域名会被当作内部处理。你也可以提供带有子目录的域名,这样该子目录及其内容也会被视为“内部”。
被视为“内部”的链接将出现在“Internal”标签页中,而不是“External”标签页,并且从中会提取出更多细节信息。
默认情况下,Screaming Frog SEO Spider 会将非网站主域名的资源(比如图片、脚本、样式表等)视为“外部链接”,包括常见的 CDN(如:cdn.example.com、images.examplecdn.net 等)。
但有些网站会把自己的核心资源托管在 CDN 上,如果这些资源不被当作“内部”,你就无法:
-
检查它们的 HTTP 状态码 -
抓取其中的图片、CSS、JS 资源 -
分析它们的标题、元标签、内容等
通过这个设置,你可以让 Screaming Frog 把这些 CDN 域名当作“内部链接”,从而对它们进行完整分析。
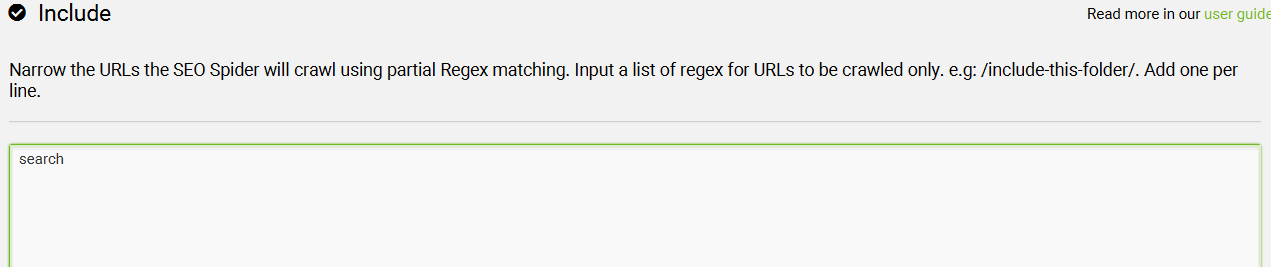
4.7、Include – 包含
这个功能允许你使用部分正则表达式匹配来控制 SEO Spider 抓取哪些 URL 路径。
例如,如果你希望只抓取 https://www.screamingfrog.co.uk 中带有 search 的 URL,可以在“Include”功能中填写正则:search
这会匹配 /search-engine-marketing/ 和 /search-engine-optimisation/,因为它们的 URL 中都包含“search”。
4.8、Exclude – 排除
该配置项允许你使用正则表达式的部分匹配规则,从网站抓取中排除某些 URL。
常见示例:

4.9、Speed – 速度
Configuration > Speed
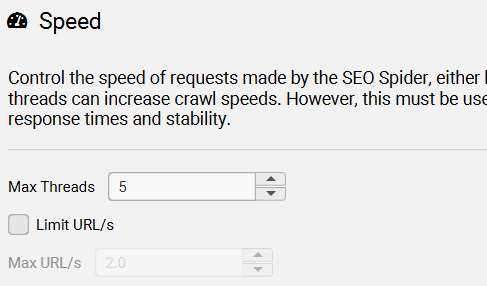
此配置允许你控制 SEO Spider 抓取的速度,可以通过两种方式调节:
- 并发线程数(Max Threads)
- 每秒请求的 URL 数量(Max URI/s)
4.10、User Agent – 用户代理
此配置允许你更改 SEO Spider 在抓取网站时使用的 User-Agent(用户代理字符串),并控制遵循哪个 robots.txt 的指令。
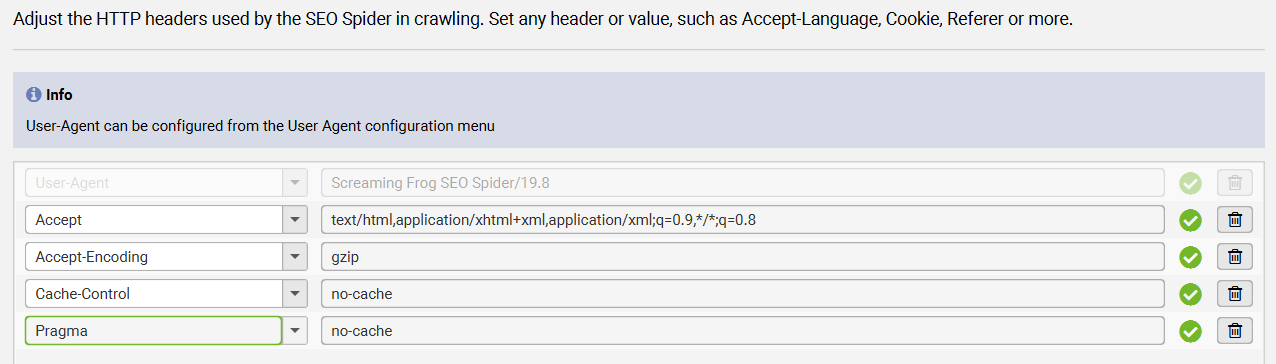
4.11、HTTP Header – HTTP头部
HTTP Header 配置允许你在抓取网站时,自定义请求头(HTTP Headers),为每一个请求添加你需要的任何 header 信息。
可设置的内容包括:
Accept-Language:指定语言偏好(如请求多语言页面时使用)Cookie:模拟登录状态或设置偏好Referer:设置来源页面
4.12、Custom – 自定义
Configuration > Custom > Search
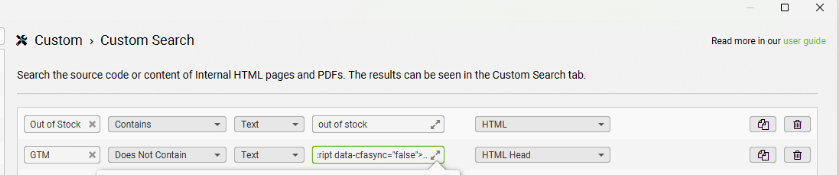
SEO Spider 提供 自定义搜索功能,可以让你在网站的 HTML 源代码或指定位置中查找任意你想要的内容(例如特定文本、代码、元素等)。非常适合用于寻找缺失内容、存在错误提示、跟踪脚本代码、状态信息等。
使用方式:
-
搜索可以设为: -
全部 HTML 源码 -
页面可见文本 -
指定 HTML 元素(如 <div>、<script>) -
XPath 选择器等
-
-
-
包含 / 不包含(contains / does not contain) -
普通文本 / 正则表达式(text / regex) -
搜索位置:
-
例如:查找包含特定字样的页面:
- 搜索 “Out of stock” 文案,找出所有缺货页面设置为:contains + text + Out of stock + HTML
Configuration > Custom > Extraction
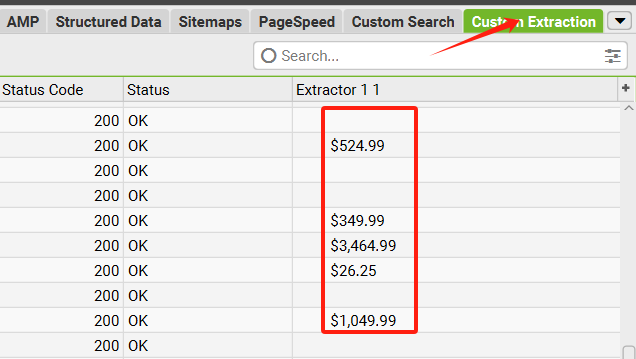
自定义提取功能允许你从网站页面的 HTML 中抓取任意结构化或非结构化数据,如产品价格、标题、元数据、评分、作者名等。
可视化提取(Visual Custom Extraction):
若你不熟悉 XPath 或 CSS 选择器,可以点击配置界面的小浏览器图标,进入内置浏览器:
-
输入你要抓取的 URL -
用鼠标点击你希望抓取的内容(如标题、作者名、价格) -
工具将自动生成推荐的 XPath、CSS 路径及预览提取结果
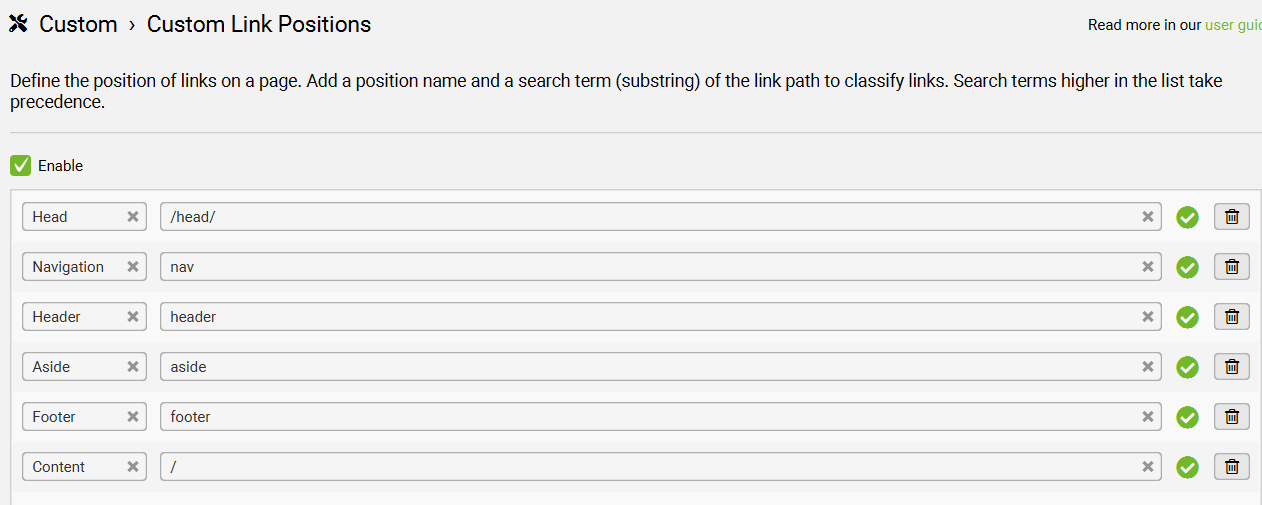
Configuration > Custom > Link Positions
Link Positions(链接位置)功能的用途在于:帮助你识别一个页面的内部链接是来自导航栏、正文、页脚、还是侧边栏等不同位置,从而进行更精准的内部链接分析、链接质量评估或SEO优化。
4.13、API Access – API访问
这个是 API Access 接口,没有功能上的使用方法,需要如何连接,请参考官方教程
https://www.screamingfrog.co.uk/seo-spider/user-guide/configuration/#google-analytics-integration
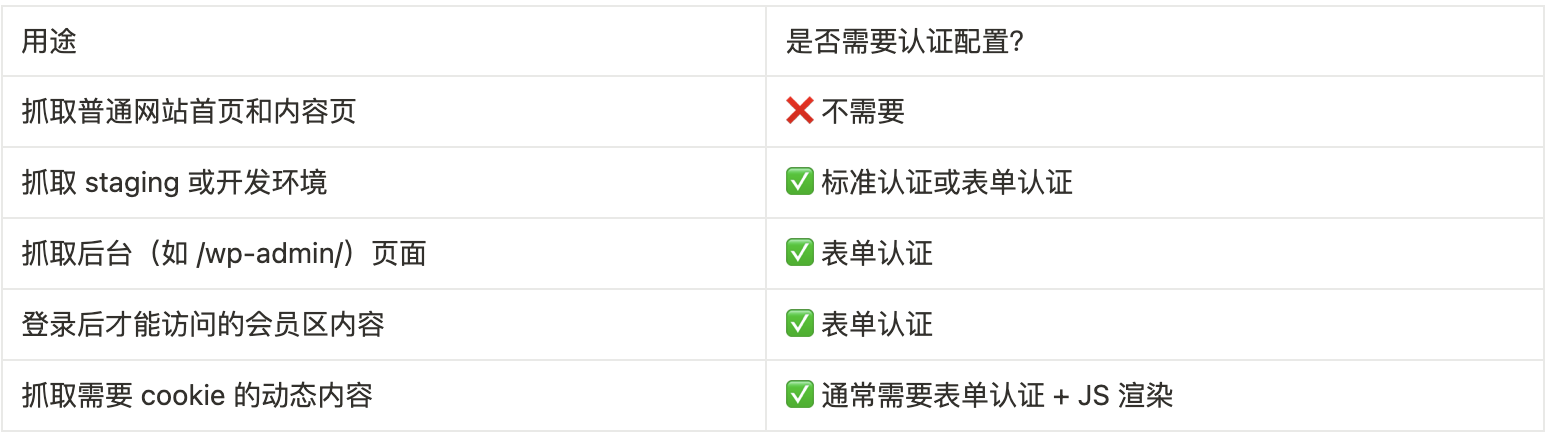
4.14、Authentication – 身份验证
Authentication(认证)配置功能,在 Screaming Frog SEO Spider 中是用来抓取需要登录的网站页面的。
抓取普通网站用不到,所以此处不做过多讲解,只需要了解一下用途即可。
4.15、Segments – 分段 / 片段
Segments(分段)功能用于将网站按不同页面类型、模板、URL 特征等划分为不同的组,以便你更有针对性地分析 SEO 问题和优化机会。
你应该在以下几种情况下使用 Segments:

前提:你必须使用 Database Storage 模式
- 设置位置:
File > Settings > Storage Mode > Database Storage - 优点是可以使用高级功能如 Segments、Compare Crawls 等
创建 Segments 的步骤:
-
打开 Screaming Frog -
确保使用 Database 模式 -
进入 Configuration > Segments -
点击 “Add” 添加一个新的 Segment -
设定规则(类似筛选器): -
例如:URL 包含 /blog/→ 设置为 “Blog 页面”
-
-
点击 “OK”,保存 Segment
4.16、Crawl Analysis – 抓取分析
Crawl Analysis 是一个 后处理分析步骤,用于计算爬虫完成后才能获得的特定数据(如 Link Score、孤立页面、内部链接深度等),并填充某些特定的过滤器和列。
在以下场景使用:
- 需要 Link Score、Inlinks、Outlinks 等高级分析
- 要分析 Sitemap 中的覆盖情况
- 需要识别孤立页面(Orphan URLs)
- 使用 Google Analytics / GSC 集成后,想找出未被链接但有流量的页面
- 想根据页面的模板、类型进行 Segment 分析
一、自动分析
-
在爬虫开始前,点击:Configuration > Crawl Analysis -
勾选底部的 Auto Analyse At End of Crawl -
完成爬虫后,系统会自动进行分析
二、手动启动分析
-
爬虫完成后,点击菜单栏:Crawl Analysis > Start -
屏幕右下方会出现进度条,表示分析正在进行
分析完成后,以下数据会被填充(之前是空的):

到此配置部分针对每一个功能是做什么的,什么场景下使用就说明完了,大家试着去用一下。由于本文内容太长,后需的文章再讲批量导出和报告部分,敬请期待!
来源公众号:深圳艾维品牌独立站营销(ID:Iwishweb)让中国优质的产品连接全球消费者。
本文由奇赞合作媒体 @品牌独立站营销专家-IWISH艾维 发布,未经许可,禁止转载、采集。
该文观点仅代表作者本人,奇赞平台仅提供信息存储空间服务。