Hello 大家好,我是Simon!
最早是从 SEO技术流 今年3月份的一篇公众号文章:AI SEO 初步指南[2025年3月版] 中了解到 LLMs.txt这个概念。
在当时,这个概念非常新,讨论的人也不是很多。
而随着GEO这个概念的持续火爆,越来越多的人开始推崇在网站中增加LLMs.txt文件,希望各大语言模型能够读取这个文件,将网站中想要被LLM记住的内容“刻印”进去,达到GEO优化的目的。
那么问题来了,LLMs.txt真的对于GEO有影响吗?
先说我的结论:不会,LLMs.txt 文件不会对GEO有直接影响!
逻辑很简单:LLMs.txt是一个由站长可以随意操纵内容的文件,这也就意味着,我们主观上把想要被AI引用的内容投喂给AI,AI可不会这么轻易买账!
这个逻辑并不是我空穴来风,瞎编出来的,关于LLMs.txt的前世今生,来龙去脉,这一篇文章给大家讲清楚!
省流版:


PART 01 / LLMs.txt的兴起与背景
LLMs.txt 标准由Jeremy Howard(Answer.AI联合创始人)发起,其实还是一种处于提议中的标准,目的是要帮助大型语言模型(LLMs)访问和解释网站的结构化内容。
它类似于大家熟知的 robots.txt 文件,两者都位于网站的根目录中,并为爬虫提供抓取指引。
LLMs.txt中的内容大概长这样:
# llms.txt ## Docs - /api.md A summary of API methods, authentication, rate limits, and example requests. - /quickstart.mdA setup guide to help developers start using the platform quickly. ## Policies - /terms.md Legal terms outlining service usage. - /returns.md Information about return eligibility and processing. ## Products - /catalog.md A structured index of product categories, SKUs, and metadata. - /sizing-guide.md A reference guide for product sizing across categories.但是,它们的目的截然不同:robots.txt 的作用是控制搜索引擎爬虫的抓取行为,而 LLMs.txt 的目的则是向大型语言模型的爬虫提供内容抓取指引。
LLMs.txt 文件的出现,源于大型语言模型的一个关键限制:LLMs无法渲染 JavaScript。LLMs 爬虫通常通过原始 HTML 推断网页的上下文。
另外请注意:Robots.txt文件已经于2022年9月份,成为了正式的网络标准,编号为RFC 9309。
来源:https://datatracker.ietf.org/doc/rfc9309/
LLMs.txt 文件的目的是用来提供一个简化的、干净的网站结构视图(甚至是核心页面内容),以方便 LLMs 爬虫访问网站的核心内容。
如果网站是使用客户端渲染(client-side rendering)技术构建的,那么 LLMs 可能完全无法显示其内容,从而降低内容被抓取排名的可能性。
简而言之,如果 LLMs 无法解析你的网页内容,网站在AI中的排名则会受到严重影响。
尽管LLMs.txt 文件的概念已经提出超过一年,但截至目前,它尚未在网络上得到广泛实施。
PART 02 / 什么是 LLMs.txt 文件?
LLMs.txt 文件的核心功能是一个文本文件,用于告知大型语言模型如何找到网站上的“好内容”。
主要作用:它的目标是通过为大语言模型提供一个策划过的高价值内容地图来消除歧义,从而使它们不必猜测哪些内容是重要的。
文件格式:LLMs.txt 本质上是一个 Markdown 格式的文档。它使用 H2 标题来整理成指向关键资源的一组链接,提供更加简化的网站信息架构,比如不包含广告、导航等非主要内容,仅提供核心信息。
文件位置:LLMs.txt 必须位于网站的根目录,例如 https://example.com/llms.txt。
PART 03 / 主流AI如何看待LLMs.txt
对于LLMs.txt标准,目前主流的大语言模型提供商的看法是:
Anthropic (Claude)
他们是唯一明确支持此标准的主要参与者,并且发布了它自己的 LLMs.txt 文件。但是,它并未明确声明其爬虫会使用该标准。
OpenAI (GPTBot)
从业内某大佬的测试来看,OpenAI 的搜索爬虫 (OAI-SearchBot) 会访问 LLMs.txt 文件,但目前来看,暂时没有看到官方确认会使用该文件。
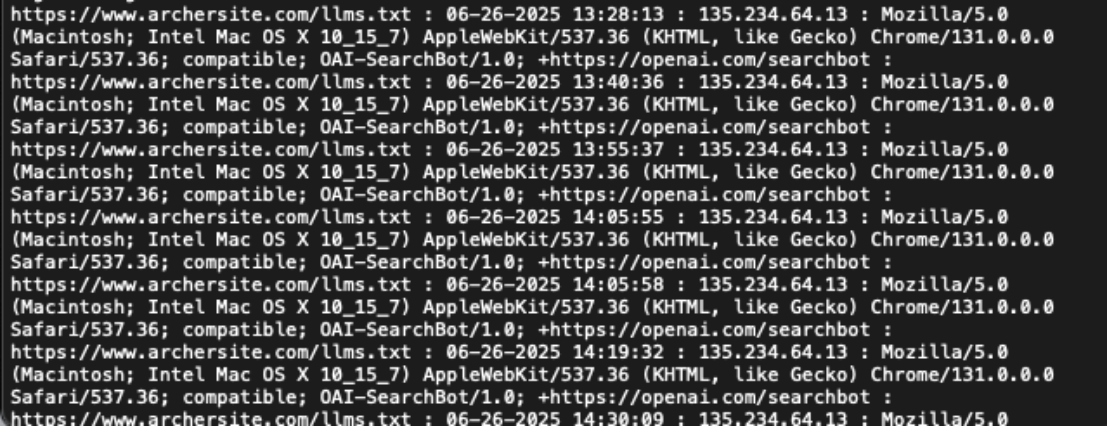
OpenAI Bot 抓取LLMs.txt文件的示例
Gary Illyes在Search Central Live上回答用户问题时,明确表示谷歌不支持 LLMs.txt,也没有计划支持。
另外,John Mueller 将 LLMs.txt 与无用的关键词 meta 标签相提并论,认为它没有实际用途,因为搜索引擎已经能够直接解析内容。
PART 04 / LLMs.txt支持VS反对
关于 LLMs.txt 文件的实际效用,业内广泛存在两种完全不同的声音。
LLMs.txt支持者观点
优化内容抓取
LLMs.txt 可以为 LLM 爬虫提供内容的“畅通无阻的路径”,尤其对于无法渲染 JavaScript 的 LLM 爬虫至关重要。
减少“AI幻觉”
通过为LLM提供相关、新鲜的内容,LLMs.txt 文件可能作为一层保障,帮助减少 LLM 模型在提供信息时的错误,
这对于需要提供高时效性的容的网站尤为重要,因为它可以提供最新内容以防止大语言模型产生“幻觉”。
易于设置,风险低
为网站设置 LLMs.txt 文件非常简单,风险很低。如果将来它成为一个被广泛采用的标准,早期采用者可能会获得小幅优势。
LLMs.txt质疑者观点
缺乏证据
目前没有证据表明 LLMs.txt 能改善 AI 搜索时的内容输出表现、增加流量或提高模型准确性。也没有主流的 LLM 提供商承诺会解析它。
冗余性
搜索引擎已经通过 robots.txt 和 sitemap.xml 等现有标准抓取并理解网站的内容。而LLMs 也使用类似的指引方式。
所以会有人(例如:John Mueller)质疑,即使网站上的内容已经能够被下载,为什么还需要一个单独的 Markdown 文件呢?
重复内容风险
有人担心 LLMs.txt 文件可能被 Google 视为重复内容。
所以谷歌的John Mueller建议:如果真要使用LLMs.txt 文件,建议使用 noindex 头部标签,以防止其内容被 Google 索引,因为这会给用户带来“奇怪”的体验。
不过一定要注意的是,使用 robots.txt 阻止 Google 爬取该文件,会导致 Google 无法看到 noindex 标签。
Spam内容风险
站长很容易在 LLMs.txt 中展示一套内容给 AI爬虫,而向用户和搜索引擎展示另一套内容,这有点类似于过去滥用的关键词 meta 标签和内容Cloaking,可能会引发搜索引擎的惩罚。
所以,如果出于这种目的滥用LLMs,txt,很容易导致搜索引擎对该文件的不信任。
浪费时间与精力投入
也有人认为,目前将精力投入到结构化数据、robots.txt 和 sitemaps 上会更有效,因为这些是已经被证明有用的标准。
PART 05 / LLMs.txt文件生成工具
既然有人对LLMs.txt感兴趣,有这个市场需求,也就自然会有人提供相应的工具,为网站创建LLMs.txt。
开源/在线工具
- Markdowner: https://github.com/supermemoryai/markdowner
- Apify LLMs.txt Generator: https://apify.com/jakub.kopecky/llmstxt-generator
- Firecrawl: https://llmstxt.firecrawl.dev/
WordPress插件
- Yoast SEO
- All in One SEO
- RankMath
- Website LLMs.txt
- LLMs.txt Generator
- LLMS Full TXT Generator
Shopify插件
- LLMs.txt Generator
- LLMS.txt AI SEO & Analytics
有意思的是,虽然一些浏览器插件开发者提供了LLMs.txt的生成功能,但是他们(例如Squirrly WordPress SEO)并不认同LLMs.txt对于网站在AI中的可见性有帮助,纯粹是因为用户的需求而增加了这个功能。
当然,也有认同这个功能的插件开发商,例如Rank Math。
PART 06 / 谁在部署LLMs.txt文件?
的确还是有一些网站部署了LLMs.txt文件,例如:
- https://answer.ai/
- https://apify.com/
- https://www.cloudflare.com/
- https://www.anthropic.com/
- https://benzinga.com/
- https://www.bitcoin.com/
- https://clerk.com/
感兴趣的朋友可以到这里搜索:https://directory.llmstxt.cloud/,当前有展示600+网站。
PART 07 / LLMs.txt对AI引用有效?
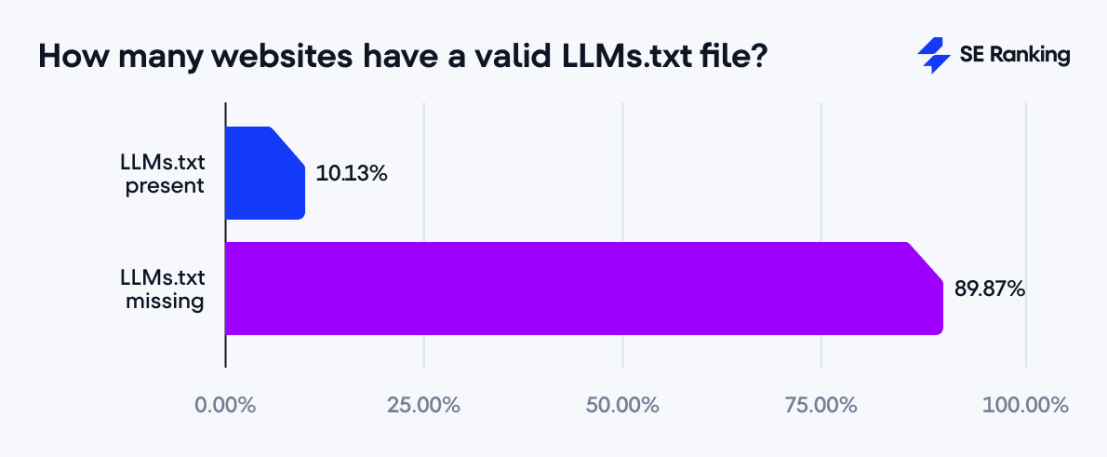
这是SERaning针对30万个域名是否部署LLMs.txt,以及这些部署了LLMs.txt网站在AI中表现的总结:
1、仅10.13%的网站有部署LLMs.txt。
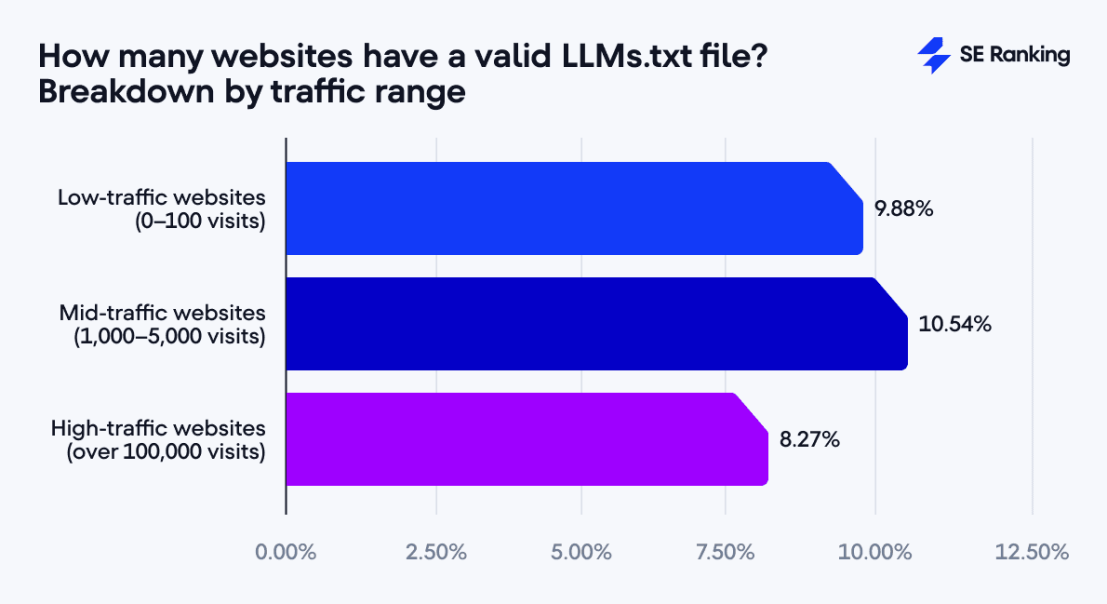
2、低流量网站部署LLMs.txt文件的比例相对较高。
3、AI引用与LLMs.txt之间没有相关性。
4、一些网站日志中显示,GPTBot有时会抓取LLMs.txt文件,但是这种情况并不常见。
PART 08 / 个人建议
我个人的建议是:
1、可以带着测试的目的去为网站部署LLMs.txt,但不需要抱以过高的期望。
2、对于网站内容属于重度依赖Javascript渲染的网站类型(例如:虚拟货币交易平台,股票信息等),也许可以尝试部署LLMs.txt文件,来帮助爬虫更好地理解网站内容。
参考资料

来源公众号: 赛门快跑(ID:SimonS_Rush)分享海外数字营销干货
本文由 @赛门快跑(苏嵩Simon) 原创发布于奇赞平台,未经许可,禁止转载、采集。
该文观点仅代表作者本人,奇赞平台仅提供信息存储空间服务。